
安装插件
前面已经升级Dify1.01,现在又已经推出1.1.1版本了
1.0版本之后支持插件功能,通过Marketplace、GitHub、本地插件3种方式
推荐一个Dify 新闻聚合插件-多平台新闻热榜获取插件rookie-rss
github地址:https://github.com/jaguarliuu/rookie-rss
授权地址我这里直接用的默认的体验站地址:https://api-hot.imsyy.top/
也可以自己部署填写只记得地址,开源项目地址:https://github.com/imsyy/DailyHotApi
配置工作流
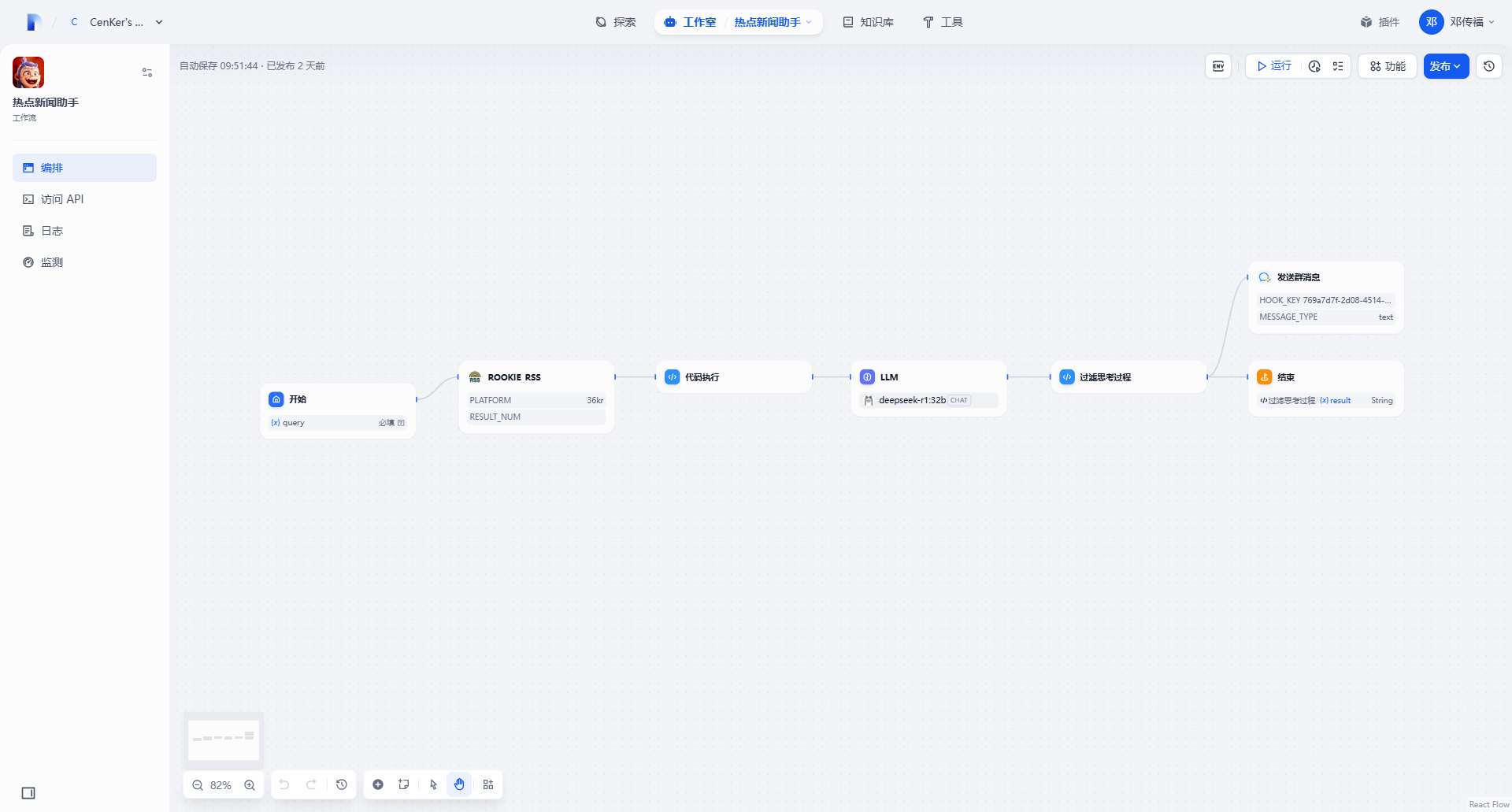
使用插件设置你的工作流,设置抓取的平台和条目
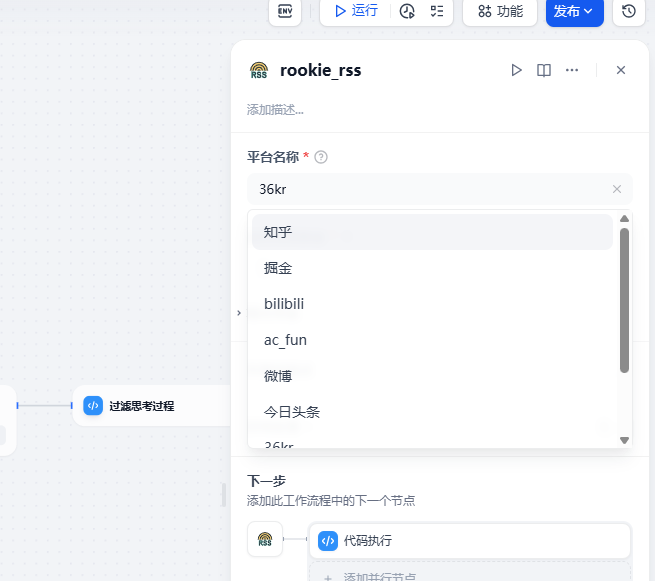
让AI写个数据处理脚本
def main(inputs):
"""终极数据处理器"""
try:
# 强化类型校验(兼容平台特殊格式)
if not isinstance(inputs, dict):
# 尝试自动修复列表型输入
if isinstance(inputs, list):
inputs = {"inputs": inputs}
else:
return {"result": "ERROR: 根节点必须为字典或列表类型"}
# 安全数据路径访问
input_list = inputs.get('inputs', [])
# 处理空数据情况
if not isinstance(input_list, list) or len(input_list) == 0:
return {"result": "警告:数据列表为空"}
# 主数据提取
primary_data = input_list[0] if isinstance(input_list, list) else {}
# 获取文章列表
articles = primary_data.get('articles', [])
if not isinstance(articles, list):
return {"result": "ERROR: 文章数据格式异常"}
# 结构化处理
output = []
for idx, article in enumerate(articles, 1):
# 防御式字段提取
safe_article = article if isinstance(article, dict) else {}
links = safe_article.get('links', {})
metadata = safe_article.get('metadata', {})
# 字段值安全处理
item = {
'author': str(safe_article.get('author', '佚名')).strip(),
'pc': str(links.get('pc', '链接缺失')).strip(),
'mobile': str(links.get('mobile', '链接缺失')).strip(),
'time': str(metadata.get('update_time', '未知时间')).replace('T', ' '),
'title': str(safe_article.get('title', '无标题')).strip()
}
# 格式化模板
block = f"""\n▶ 条目 {idx} ◀
作者:{item['author']}
电脑版:{item['pc']}
手机版:{item['mobile']}
更新时间:{item['time']}
{'-'*25}
{item['title']}
{'-'*40}"""
output.append(block)
return {"result": '\n'.join(output) if output else "无有效内容"}
except Exception as e:
return {"result": f"系统异常:{type(e).__name__}({str(e)})"}
# 超级兼容入口
if __name__ == '__main__':
try:
# 动态输入获取(兼容所有平台格式)
raw_input = globals().get('inputs') or locals().get('inputs') or {}
# 自动格式转换
if isinstance(raw_input, list):
workflow_inputs = {"inputs": raw_input}
elif 'inputs' not in raw_input and 'articles' in raw_input:
workflow_inputs = {"inputs": [raw_input]} # 兼容无嵌套格式
else:
workflow_inputs = raw_input
# 执行主逻辑
output = main(workflow_inputs)
# 最终输出标准化
result = output if isinstance(output, dict) else {"result": str(output)}
result['result'] = result.get('result', '未知状态').strip()
except Exception as e:
result = {"result": f"致命错误:{e.__class__.__name__}"}
告诉大模型输出格式
请将提供的新闻数据{{#context#}}按以下要求格式化为易读的热点新闻列表:
1. **列表结构**
- 每个条目包含:
• 标题
• 新闻链接(pc端地址)
2. **格式规范**
标题:`[标题文本]`
新闻链接:`PC链接地址`
新闻链接链接禁止换行
必须检查新闻链接中是否有空格,有空格一定要删除;
3. **样式要求**
- 在列表开头添加`📊 36Kr新闻热榜TOP5`标题
示例输出格式:
📊 36Kr新闻热榜TOP5
1、[新闻1标题]
-新闻链接:链接
2、[新闻2标题]
-新闻链接:链接
3、[新闻3标题]
-新闻链接:链接
过滤掉Deepseek的推理过程
import re
def main(query: str, answer: str) -> dict:
cleaned_answer = re.sub(r'<think[^>]*>.*?</think>', '', answer, flags=re.DOTALL)
final_answer = re.sub(r'^\n+', '', cleaned_answer)
return {
"result": final_answer,
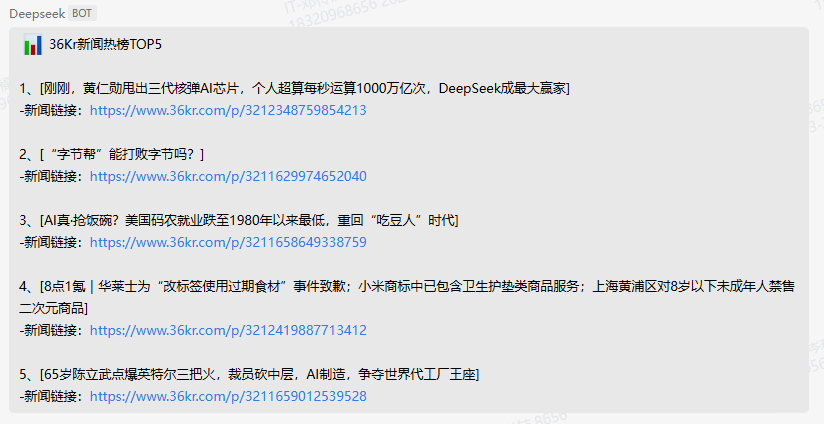
}通过企微webhook机器人推送到群里
定时执行工作流
现在工作流走通了,输出效果也是我们要的,但是不可能每天自己手动来Dify执行一下工作流吧。
我直接在服务器丢个定时任务每天 8:00 执行脚本去请求Workflow 应用 API
我在/data/dify下新建了个news.sh
后端API秘钥在你的工作流监测-后端服务API新建,API地址也在这。
curl -X POST 'http://xxxxxxxxxxxx/v1/workflows/run' \
--header 'Authorization: Bearer app-zImizONgGxxxxxxxxxxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {"query":"1"},
"response_mode": "streaming",
"user": "每天8:00查询新闻热榜"
}'编辑定时任务,我这里是每天八点执行脚本,crontab -e
0 8 * * * bash /data/dify/news.sh > /dev/null 2>&1自动推送效果
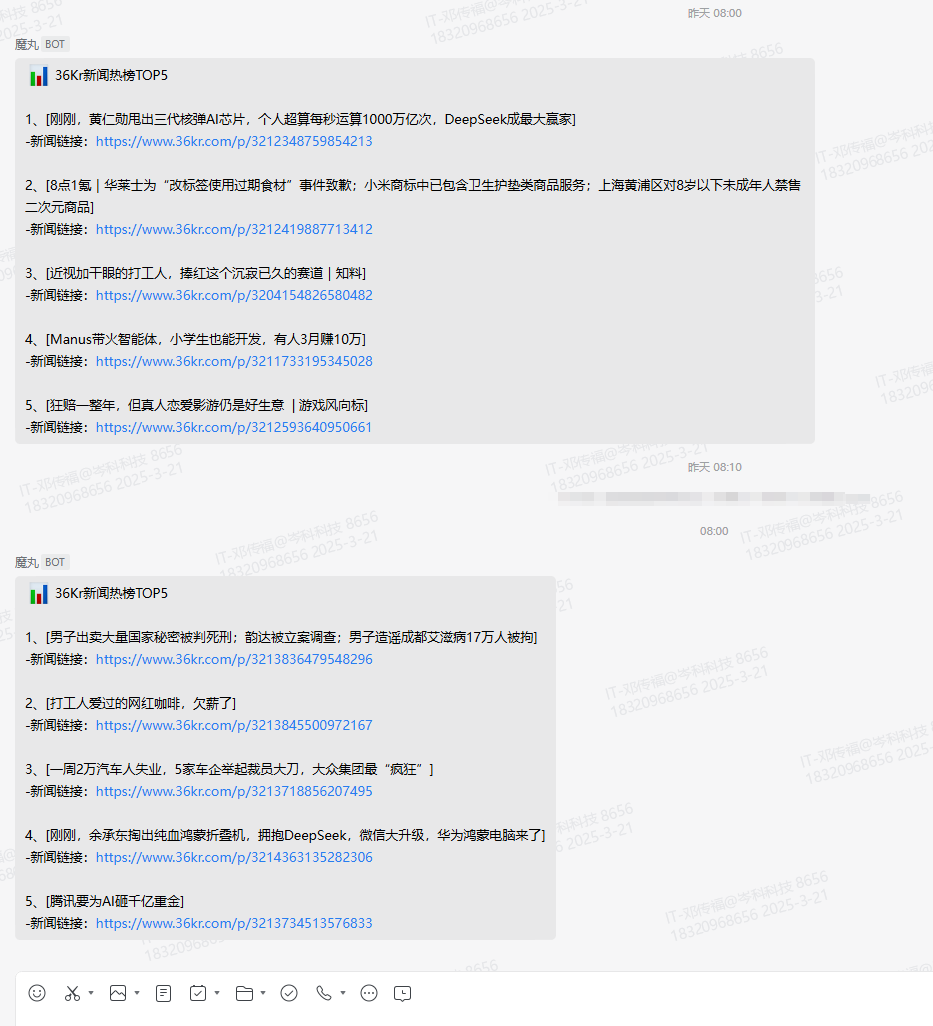


评论区